Mastering ProjectTemplate
Before you work through this walkthrough, you should make sure you’ve read (or at least understood) the contents of the beginner’s tutorial.
Ad Hoc File Types
In the beginner’s tutorial, we showed how ProjectTemplate automatically loads data files from the data and cache directories. If you’re working with plain text files or any of the supported binary file formats, this automatic data loading should work out of the box without any effort on your part. But if you have to retrieve data sets from more complex data sources, ProjectTemplate has advanced features that will let you set up ad hoc autoloading. In the rest of this document, we’ll talk about working with SQL databases, remote resources available over HTTP and FTP, large data files stored on external drives and R files that contain code that generates data at runtime.
SQLite Databases
Let’s start by working with a SQLite database. We’ll use a database from the Analytics X competition in which contestants were trying to predict crimes that took place in Philadelphia. You can download the database file here. To save on bandwidth, we’ve compressed the database, so you should uncompress it before going through the rest of this tutorial.
Autoloading the Database
The simplest way to access the database is to store the philapd.db file in the data directory of a new project. Let’s set up a project using the standard ProjectTemplate invocation:
> library('ProjectTemplate')
> create.project('PhilaPD')
Then we’ll shift into the relevant directory, move our database over and uncompress it:
$ cd PhilaPD
$ mv ~/Downloads/philapd.db.zip data
$ unzip data/philapd.db.zip -d data
$ rm data/philapd.db.zip
Then we reload R and load the project. You’ll see ProjectTemplate automatically load the two tables found in our SQLite database:
> library('ProjectTemplate')
> load.project()
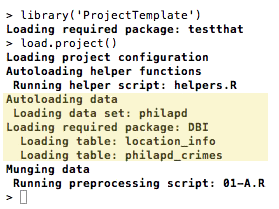
For most users, this automatic loading procedure is probably enough. But if you need more fine-grained control, you can use the .sql ad hoc file type to load specific tables from a SQLite database. You can also specify an exact SQL query to run against the database. We’ll go through all three cases below.
Load One Specific Table
First, let’s move the philapd.db file out of the data directory to prevent it from being autoloaded:
$ mv data/philapd.db .
After that, we’ll create an .sql file in the data directory. We’ll use a file called data/philapd.sql. Inside of this file, we need to specify (a) that we’re working with a SQLite database, (b) the path to the SQLite database and (c) the specific table we want to load. We’ve done that below:
type: sqlite
dbname: philapd.db
table: location_info
After creating the data/philapd.sql file, we can rerun load.project, which will load only the location_info table from our database into the variable philapd:
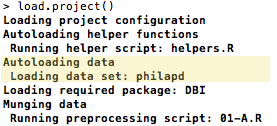
Load All Tables from a Specific Database
If we want to load all of the tables from a database file that we can’t place inside of the data directory, we can use a .sql file to do this by replacing the name of a specific table with an asterisk:
type: sqlite
dbname: philapd.db
table: *
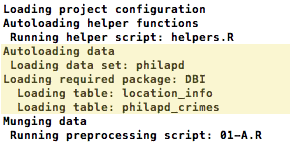
Loading Data with an SQL Query
You can also load a subset of your data by specifying an SQL query instead of a table in your .sql file:
type: sqlite
dbname: philapd.db
query: SELECT * FROM location_info WHERE zip = '19144'
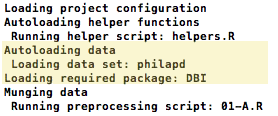
MySQL, PostGres or ODBC Databases
Working with a MySQL, PostGres or ODBC database is exactly as easy as using a .sql file to access a SQLite database. All that changes is the use of the mysql, postgres or odbc types instead of the sqlite type:
type: mysql
user: sample_user
password: sample_password
host: localhost
dbname: philapd
table: location_info
type: postgres
user: sample_user
password: sample_password
host: localhost
dbname: philapd
table: location_info
type: odbc
user: sample_user
password: sample_password
host: localhost
dbname: philapd
table: location_info
URL Files
If you need to access a file that’s available over HTTP or FTP, you can use a .url file. Inside of the file, you’ll specify the URL where your data set is available and the type of data set you’re accessing. Here, we’ll use a data/sample.url file to load the standard ProjectTemplate sample data set over HTTP:
url: http://www.johnmyleswhite.com/ProjectTemplate/sample_data.csv
separator: ,
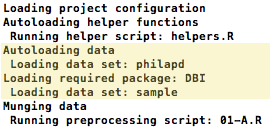
.file Files
If you need to access a file that’s stored outside of the project’s main directory, you use a .file file. Inside of the file, you’ll specify the path of the data file and the extension of the data set you’re accessing:
path: /usr/share/dict/words
extension: csv
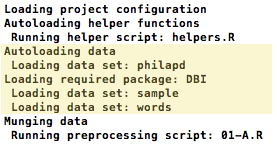
R Files
Sometimes you want to generate random data for your analysis: this, after all, is the heart of Monte Carlo analyses of statistical methods. You can do this by inserting R code into a file in the data directory. We’ll put this into the data/d.R file:
set.seed(1)
d <- rnorm(1000, 0, 1)
Media Files: MP3’s and PPM’s
Sometimes you want to work with more interesting sorts of data than a typical text file. ProjectTemplate now has basic support for loading media files into R. To load an MP3 audio file into an R object for analysis, simply place the .mp3 file in the data directory. The tuneR package will be automatically loaded by ProjectTemplate and the MP3 file will be read into an R object in the global environment. Similarly, if you want to load a PPM image file, just place the .ppm file into the data directory. ProjectTemplate will then use the pixmap package to load the image file into an R object in the global environment.
Unit Testing Your Project
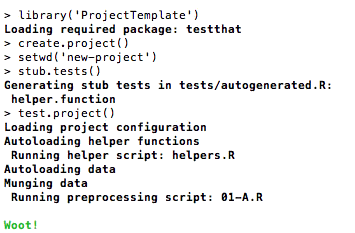
ProjectTemplate has been designed to make it easier to unit test the functions you’ve written for your analysis. To get started, you can call stub.tests(), which will generate a file at tests/autogenerated.R filled with sample tests for every one of the functions you defined inside of the lib directory. You should edit these tests, as they are expected to fail by default.
After editing your tests, you can call test.project() to run all of the unit tests in the tests directory 1.
Logging Your Work
If you want to log your work, ProjectTemplate will automatically load a log4r logger object into the logger variable that will write to a plain text stored at the logs/project.log. To use this logger, you only need to change the configuration file to specify:
logging: TRUE
After making this change, the logger object will be created once you call load.project():
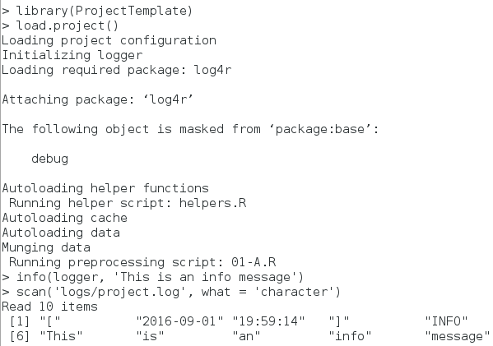
The default loglevel can be set through the configuration file by setting the
logging_level flag to one of the valid levels for log4r, by default it is
set to “INFO”
Data Tables
The data.table package allows you to create a variant of the typical R data frame that provides indices. Indices make locating and selecting subsets of your data much faster than the typical vector scan that R uses when working with data frames. To automatically convert all of the data frames loaded from the data directory into data.tables, change the configuration option in config/global.dcf to data_tables: on. After that, you can check for tables by calling the tables() function.
Ignoring files
Sometimes files in the data/ directory should be ignored while loading the
data. A notorious example in Windows™ is the creation of Thumbs.db a
file containing thumbnail previews of the files in the folder. By default .db
files are imported as SQLite databases, which fails for Thumbs.db.
To overcome this the option data_ignore in config/global.dcf allows to
specify files or folders to ignore. The patterns are separated by commas, and
come in three different flavours:
- Literal filename: Simply specify a filename, like
Thumbs.dbin the default settings, and it will be excluded. If you haverecursive_loadingenabled make sure you add the path to the file, relative to thedata/directory. So to ignore the filetest.csvin the folderdata/more-data/you addmore-data/test.csvto the list.
A wildcard*is allowed in literal filenames to match multiple characters. So to ignore all.csvfiles under thedata/directory and subdirectories you add*.csv, and to ignore them only in the folderdata/test-data/you change the pattern totest-data/*.csv. - Literal directory: Specify the directoryname relative to the
data/directory, and add a trailing/. To ignore the directorydata/raw/entirely add the the patternraw/. The*wildcard is allowed in directory patterns as well. - Regular expression: For advanced patterns it is possible to use regular
expressions. Regular expressions have to inserted between two slashes.
Expressions are evaluated with option
perl = TRUE. You should not escape backslashes inglobal.dcf, unless a literal\is meant. The filenames are evaluated individually so it is not possible to use forward or backward references to other files in the same directory.
This can for example be used to exclude a filename from a thedata/directory and all subdirectories. To ignorehelp.txtin all folders use the pattern/^(.*/)?help\\.txt$/. Explaining all possibilities of regular expressions is too much for this page, see ‘Perl-like Regular Expressions’ under?base::regexfor more information.
Listing data
When encoutering unexpected results from load.project in the load data phase
it can be useful to have some insight in what files are found by load.project
and which reader is used to import the data. For this purpose the list.data
function returns a list of all files, with metadata on how the variable will be
called, whether it is in the cache, whether it matches a data_ignore pattern,
and what reader will be used. list.data doesn’t actually read the files so it
is much quicker than a call to load.project.
Note that variables in the cache are matched to filenames in data/
recursively, after which only files are displayed by list.data that match the
recursive_loading setting in config/global.dcf. This ensures that ignored
variables from a nested folder in data/ don’t get loaded from cache. As a
consequence, some variables visible by list.files('cache') might not show up
in the output of list.data if recursive_loading is set to FALSE.
-
Some versions of
TestThatmay required thatload.project()is run beforestub.tests()↩